Sprachpakete hinzufügen
In der Grundinstallation verfügt Stirling-PDF nur über das englischsprachige Paket für die Texterkennung.
Um bspw. deutschsprachige Texte verarbeiten zu können, bedarf es somit weiterer Sprachpakete.
Die optionalen Sprachpakete befinden sich unterhalb des Installationsverzeichnisses (hier /srv/stirling) im Verzeichnis trainingData.
Daher wird zunächst in dieses Verzeichnis gewechselt, das nach der Installation noch leer ist:
Auf der Übersichtsseite aller verfügbaren Sprachpakete wird die URL des zu installierenden Paketes (in diesem Beispiel deutsch) ermittelt und kopiert:
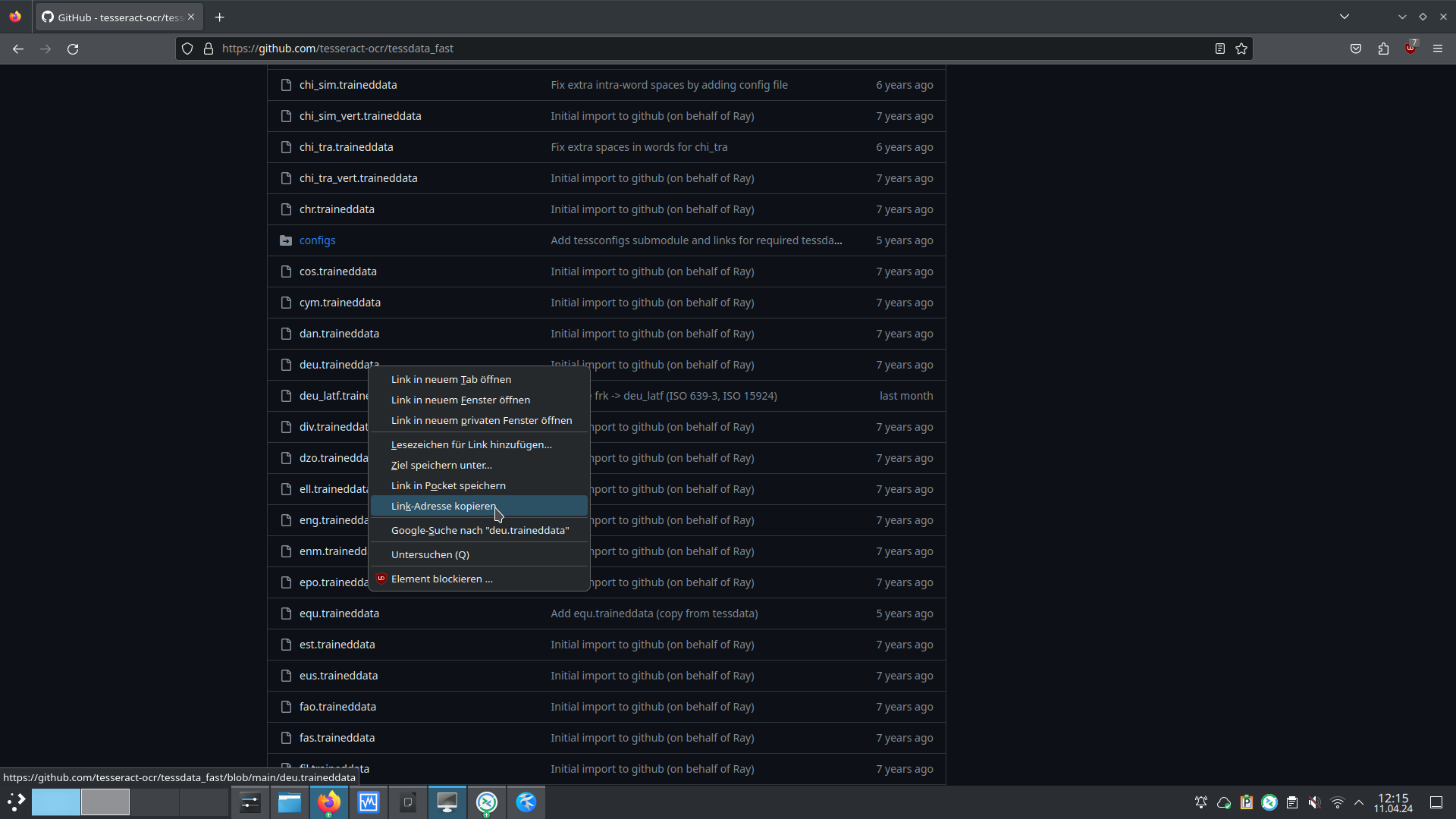
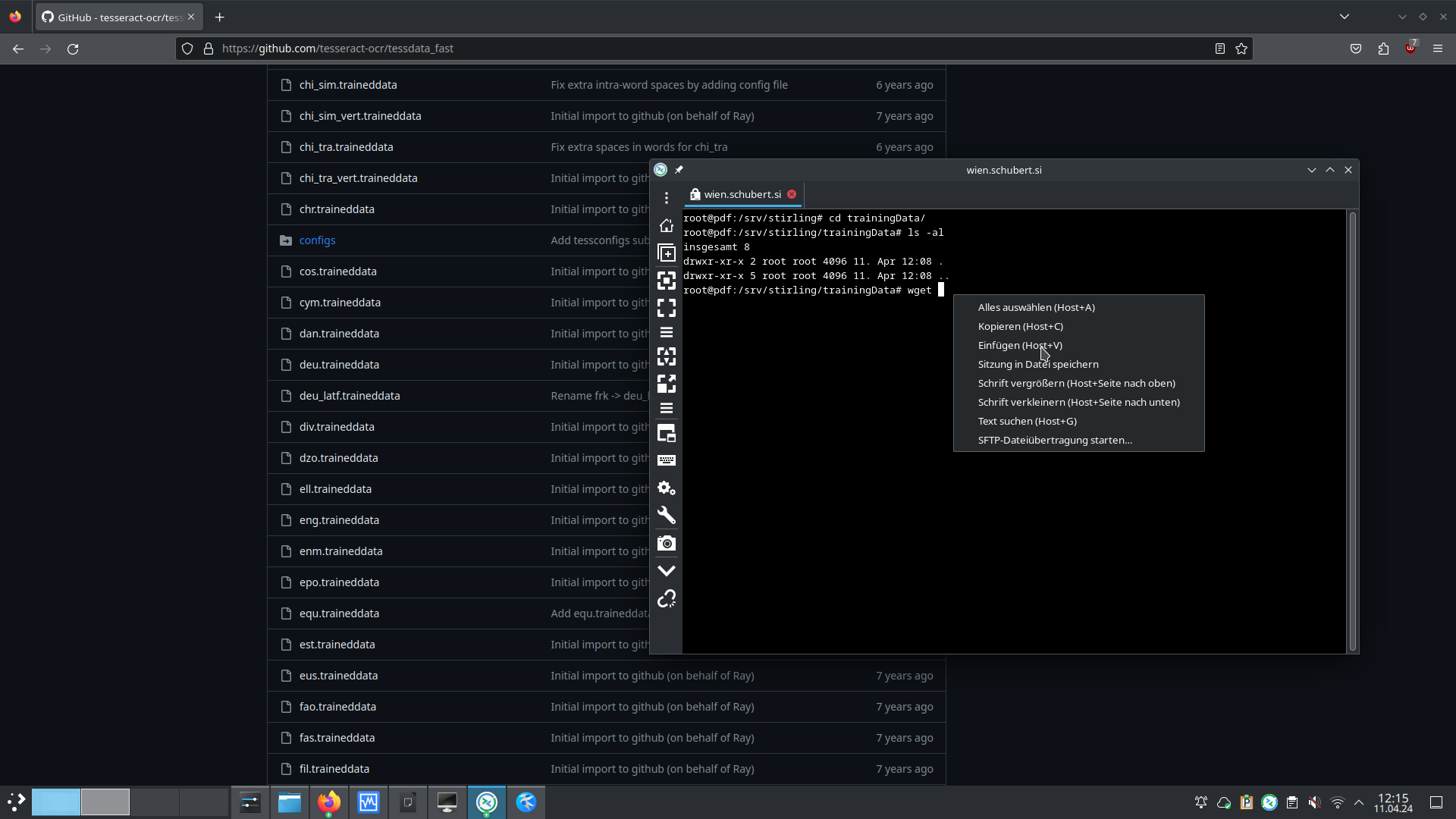
Im Verzeichnis der Sprachpakete kann die gewünschte Datei dann mittels wget URL empfangen werden.
Für das Beispiel lautet der gesamte Befehl somit wget https://github.com/tesseract-ocr/tessdata_fast/blob/main/deu.traineddata.
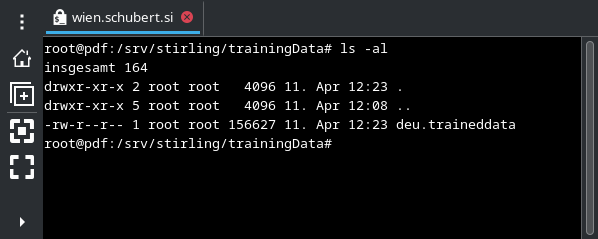
Nach dem Download enthält das Verzeichnis trainingData die entsprechende Sprachdatei:
Obwohl die Datei jetzt vorhanden ist, weiß die Anwendung (Stirling-PDF) noch nichts von ihr.
Hierfür muss abschließend der Container neu gestartet werden.
Im ersten Schritt wird die laufende Anwendung per docker-compose down heruntergefahren und im zweiten Schritt durch docker-compose up -d wieder gestartet.
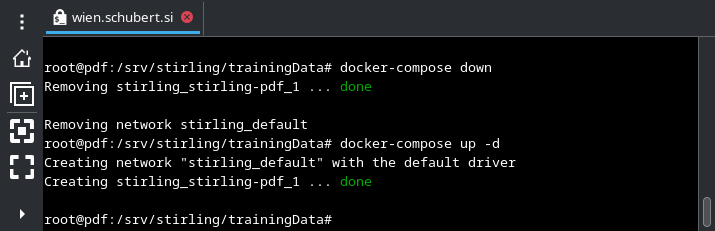
Das zusätzliche Sprachpaket steht Stirling-PDF ab sofort zur Verfügung.